
文章目录
一、监控系统概论
监控系统在这里特指对数据中心的监控,主要针对数据中心内的硬件和软件进行监控和告警。企业的 IT 架构逐步从传统的物理服务器,迁移到以虚拟机为主导的 IaaS 云。无论基础架构如何调整,都离不开监控系统的支持。
不仅如此。越来越复杂的数据中心环境对监控系统提出了更越来越高的要求:需要监控不同的对象,例如容器,分布式存储,SDN网络,分布式系统。各种应用程序等,种类繁多,还需要采集和存储大量的监控数据,例如每天数TB数据的采集汇总。以及基于这些监控数据的智能分析,告警及预警等。
在每个企业的数据中心内,或多或少都会使用一些开源或者商业的监控系统。从监控对象的角度来看,可以将监控分为网络监控,存储监控,服务器监控和应用监控等,因为需要监控数据中心的各个方面。所以监控系统需要做到面面俱到,在数据中心中充当“天眼“角色。



二、基础资源监控
2.1、网络监控
网络性能监控:主要涉及网络监测,网络实时流量监控(网络延迟、访问量、成功率)和历史数据统计、汇总和历史数据分析等功能。
网络检测*:主要针对内网或者外网的网络***。如DDoS的。通过分析异常流量来确定网络行为。
设备监控:主要针对数据中心内的多种网络设备进行监控。包括路由器,防火墙和交换机等硬件设备,可以通过snmp等协议收集数据。
2.2、存储监控
存储性能监控方面:存储通常监控块的读写速率,IOPS。读写延迟,磁盘用量等;文件存储通常监控文件系统inode。读写速度、目录权限等。
存储系统监控方面:不同的存储系统有不同的指标,例如,对于ceph存储需要监控OSD, MON的运行状态,各种状态pg的数量以及集群IOPS等信息。
存储设备监控方面:对于构建在x86服务器上的存储设备,设备监控通过每个存储节点上的采集器统一收集磁盘、SSD、网卡等设备信息;存储厂商以黑盒方式提供商业存储设备,通常自带监控功能,可监控设备的运行状态,性能和容量的。
2.3、服务器监控
CPU:涉及整个 CPU 的使用量、用户态百分比、内核态百分比,每个 CPU 的使用量、等待队列长度、I/O 等待百分比、CPU 消耗最多的进程、上下文切换次数、缓存命中率等。
内存:涉及内存的使用量、剩余量、内存占用最高的进程、交换分区大小、缺页异常等。
网络 I/O:涉及每个网卡的上行流量、下行流量、网络延迟、丢包率等。
磁盘 I/O:涉及硬盘的读写速率、IOPS、磁盘用量、读写延迟等。
2.4、中间件监控
消息中间件: RabbitMQ、Kafka
Web 服务中间件:Tomcat、Jetty
缓存中间件:Redis、Memcached
数据库中间件:MySQL、PostgreSQL
2.5、应用程序监控(APM)
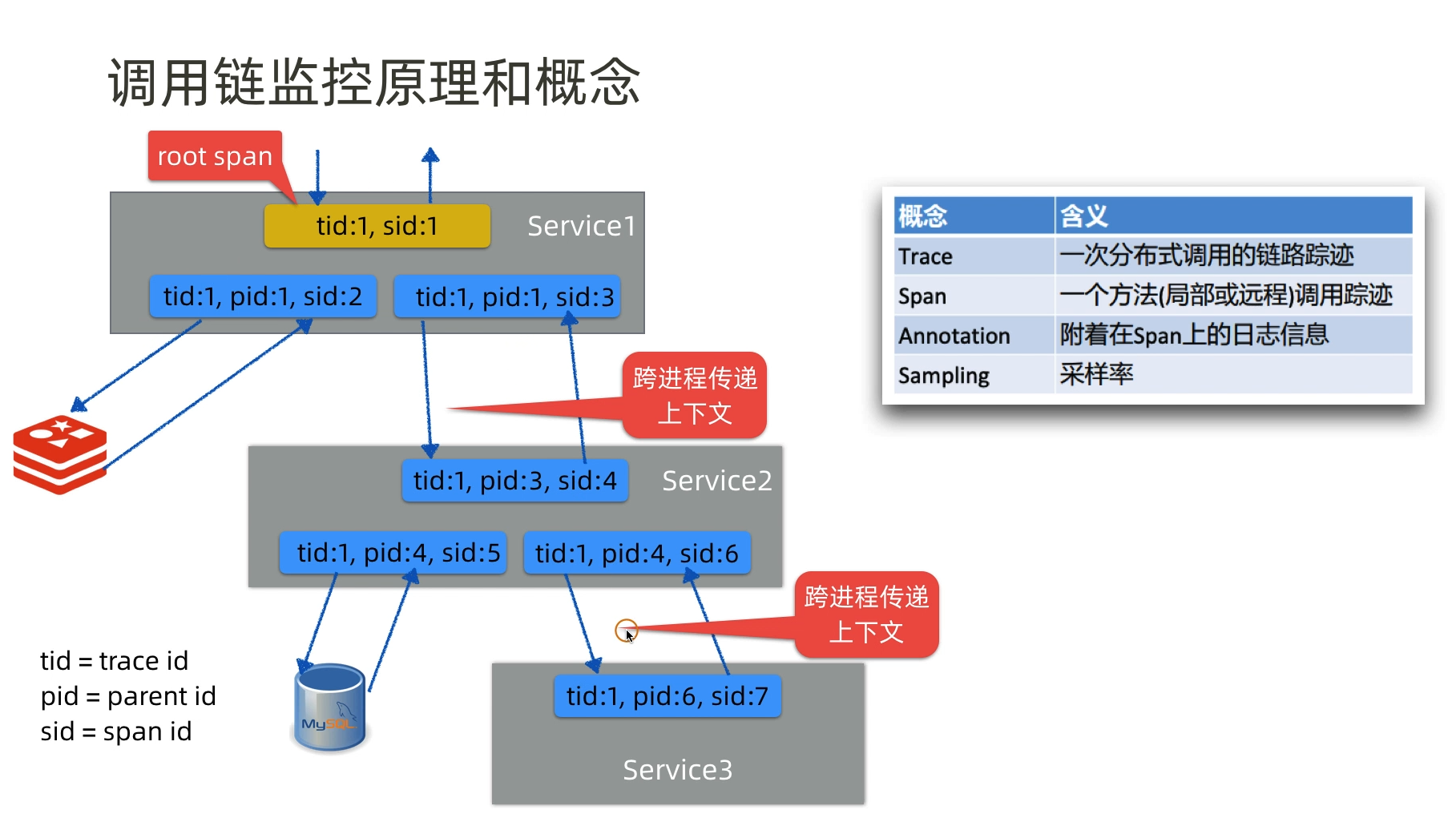
APM主要是针对应用程序的监控,包括应用程序的运行状态监控,性能监控,日志监控及调用链跟踪等。调用链跟踪是指追踪整个请求过程(从用户发送请求,通常指浏览器或者应用客户端)到后端API服务以及API服务和关联的中间件,或者其他组件之间的调用,构建出一个完整的调用拓扑结构,不仅如此,APM 还可以监控组件内部方法的调用层次(Controller–>service–>Dao)获取每个函数的执行耗时,从而为性能调优提供数据支撑。
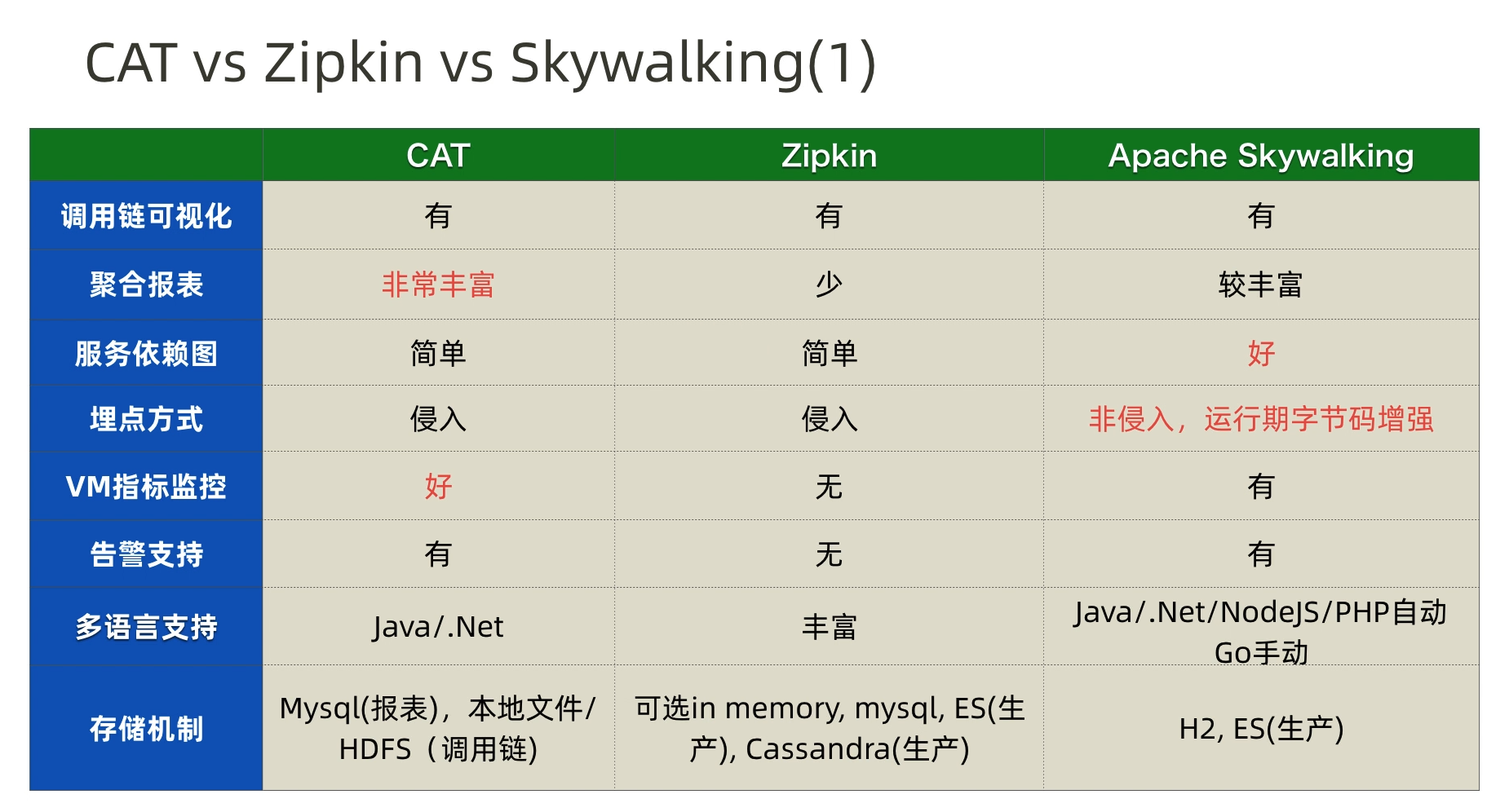
应用程序监控工具除了有 Pinpoint,还有 Twitter 开源的 Zipkin,Apache SkyWalking,美团开源的 CAT等。
调用键监控
几款产品对比

Pinpoint

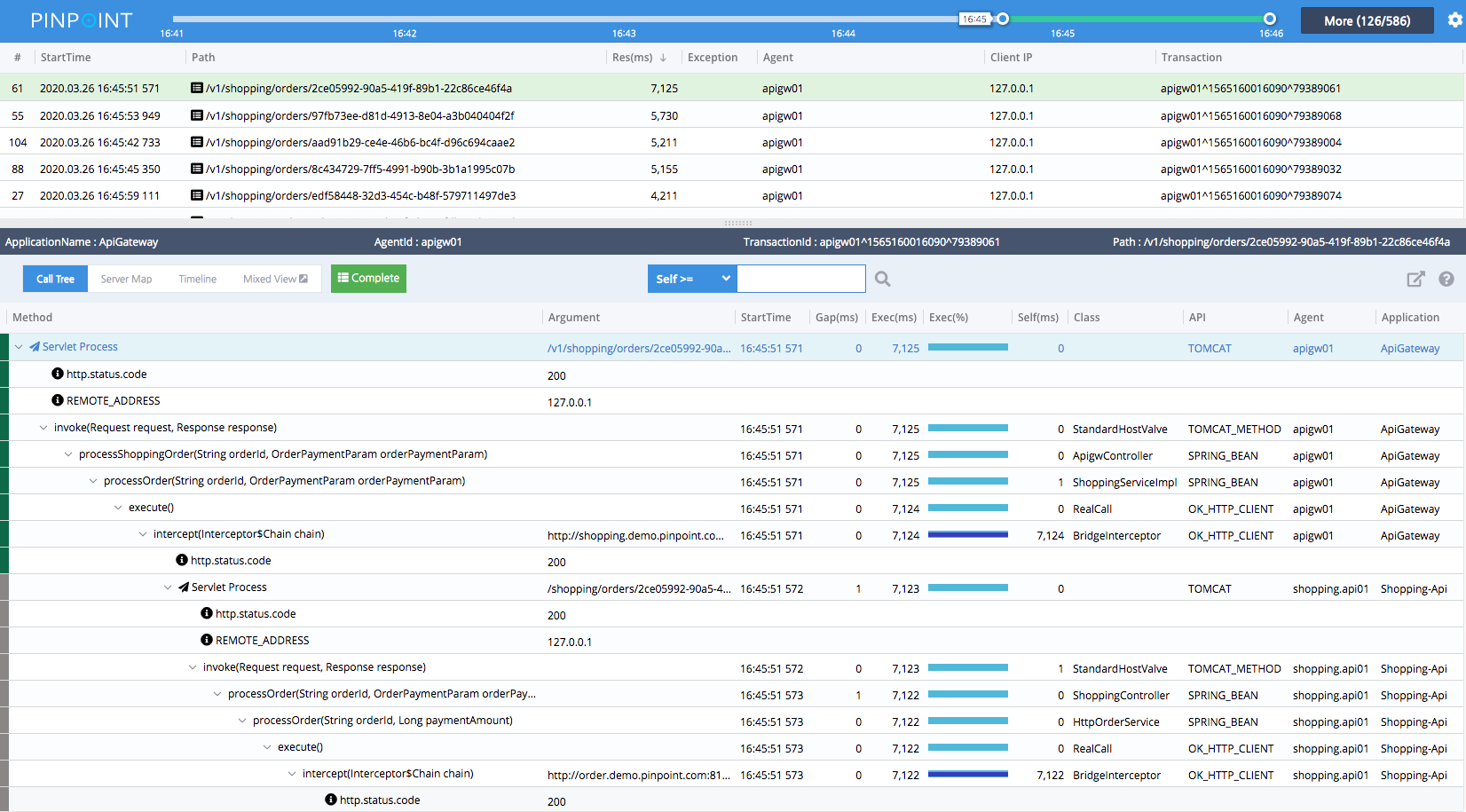
通过 APM 除了可以截获方法调用,还可以截获TCP、HTTP网络请求,从而获得执行耗时最长的方法和 SQL 语句、延迟最大的 API 的信息。
三、Prometheus 简介
3.1、什么是 Prometheus
Prometheus 是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
3.2、优点
强大的多维度数据模型:
时间序列数据通过 metric 名和键值对来区分。
所有的 metrics 都可以设置任意的多维标签。
数据模型更随意,不需要刻意设置为以点分隔的字符串。
可以对数据模型进行聚合,切割和切片操作。
支持双精度浮点类型,标签可以设为全 unicode。
灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作。
易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
高效:平均每个采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
使用 pull 模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的 metrics。
可以采用 push gateway 的方式把时间序列数据推送至 Prometheus server 端。
可以通过服务发现或者静态配置去获取监控的 targets。
有多种可视化图形界面。
易于伸缩。
3.3、组件
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
Prometheus Server: 用于收集和存储时间序列数据。
Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
一些其他的工具。
3.4、架构
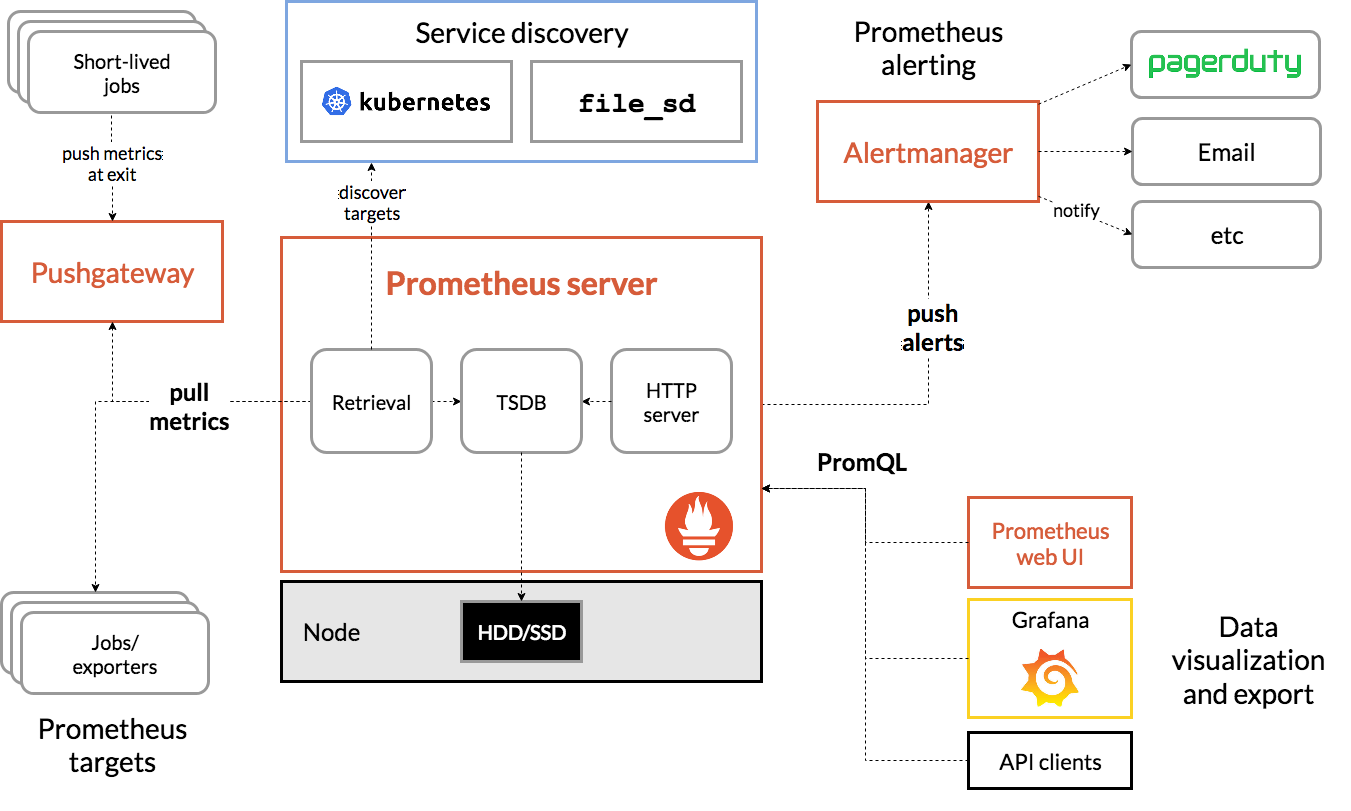
从这个架构图,也可以看出 Prometheus 的主要模块包含, Server, Exporters, Pushgateway, PromQL, Alertmanager, WebUI 等。
它大致使用逻辑是这样:
- Prometheus server 定期从静态配置的 targets 或者服务发现的 targets 拉取数据。
- 当新拉取的数据大于配置内存缓存区的时候,Prometheus 会将数据持久化到磁盘(如果使用 remote storage 将持久化到云端)。
- Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert 推送到配置的 Alertmanager。
- Alertmanager 收到警告的时候,可以根据配置,聚合,去重,降噪,最后发送警告。
- 可以使用 API, Prometheus Console 或者 Grafana 查询和聚合数据。
3.5、适用于什么场景
Prometheus 适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。在微服务的世界中,它对多维数据收集和查询的支持有特殊优势。Prometheus 是专为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个 Prometheus Server 都是相互独立的,不依赖于网络存储或其他远程服务。当基础架构出现故障时,你可以通过 Prometheus 快速定位故障点,而且不会消耗大量的基础架构资源。
3.6、不适合什么场景
Prometheus 非常重视可靠性,即使在出现故障的情况下,你也可以随时查看有关系统的可用统计信息。如果你需要百分之百的准确度,例如按请求数量计费,那么 Prometheus 不太适合你,因为它收集的数据可能不够详细完整。这种情况下,你最好使用其他系统来收集和分析数据以进行计费,并使用 Prometheus 来监控系统的其余部分。
四、数据模型
4.1、数据模型
Prometheus 所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB):属于同一指标名称,同一标签集合的、有时间戳标记的数据流。除了存储的时间序列,Prometheus 还可以根据查询请求产生临时的、衍生的时间序列作为返回结果。
指标名称和标签
每一条时间序列由指标名称(Metrics Name)以及一组标签(键值对)唯一标识。其中指标的名称(metric name)可以反映被监控样本的含义(例如,http_requests_total — 表示当前系统接收到的 HTTP 请求总量),指标名称只能由 ASCII 字符、数字、下划线以及冒号组成,同时必须匹配正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
[info] 注意
冒号用来表示用户自定义的记录规则,不能在 exporter 中或监控对象直接暴露的指标中使用冒号来定义指标名称。
通过使用标签,Prometheus 开启了强大的多维数据模型:对于相同的指标名称,通过不同标签列表的集合,会形成特定的度量维度实例(例如:所有包含度量名称为 /api/tracks 的 http 请求,打上 method=POST 的标签,就会形成具体的 http 请求)。该查询语言在这些指标和标签列表的基础上进行过滤和聚合。改变任何度量指标上的任何标签值(包括添加或删除指标),都会创建新的时间序列。
标签的名称只能由 ASCII 字符、数字以及下划线组成并满足正则表达式 [a-zA-Z_][a-zA-Z0-9_]*。其中以 __ 作为前缀的标签,是系统保留的关键字,只能在系统内部使用。标签的值则可以包含任何 Unicode 编码的字符。
时序样本
在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):指标名称和描述当前样本特征的 labelsets;
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value): 一个 folat64 的浮点型数据表示当前样本的值。
格式
通过如下表达方式表示指定指标名称和指定标签集合的时间序列:
<metric name>{<label name>=<label value>, ...}
例如,指标名称为 api_http_requests_total,标签为 method=“POST” 和 handler=“/messages” 的时间序列可以表示为:
api_http_requests_total{method="POST", handler="/messages"}
这与 OpenTSDB 中使用的标记法相同。
4.2、指标类型
Prometheus 的客户端库中提供了四种核心的指标类型。但这些类型只是在客户端库(客户端可以根据不同的数据类型调用不同的 API 接口)和在线协议中,实际在 Prometheus server 中并不对指标类型进行区分,而是简单地把这些指标统一视为无类型的时间序列。不过,将来我们会努力改变这一现状的。
Counter
一种累加的 metric,典型的应用如:请求的个数,结束的任务数, 出现的错误数等等。
例如 Prometheus server 中 http_requests_total, 表示 Prometheus 处理的 http 请求总数,我们可以使用 delta, 很容易得到任意区间数据的增量,这个会在 PromQL 一节中细讲。
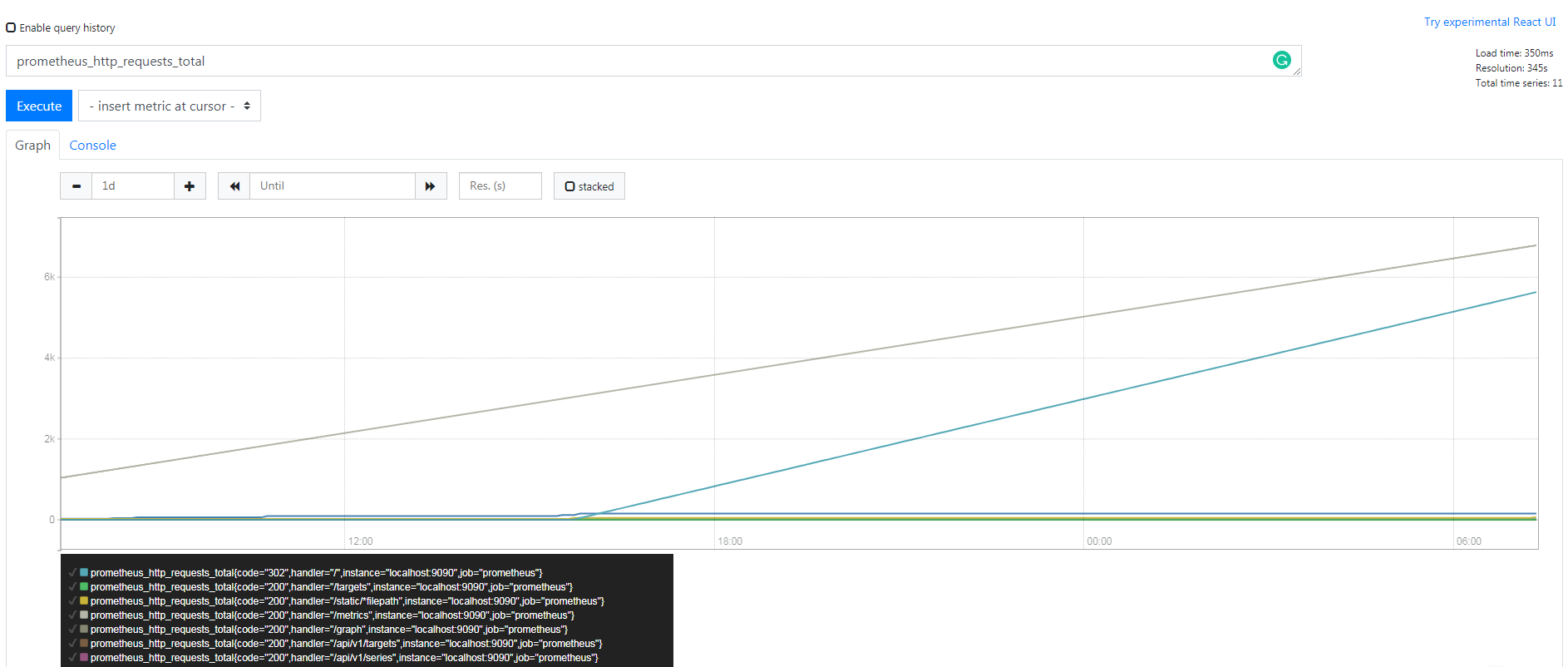
Gauge
- 一种常规的 metric,典型的应用如:温度,运行的 goroutines 的个数。
- 可以任意加减。
例如 Prometheus server 中 go_goroutines, 表示 Prometheus 当前 goroutines 的数量。
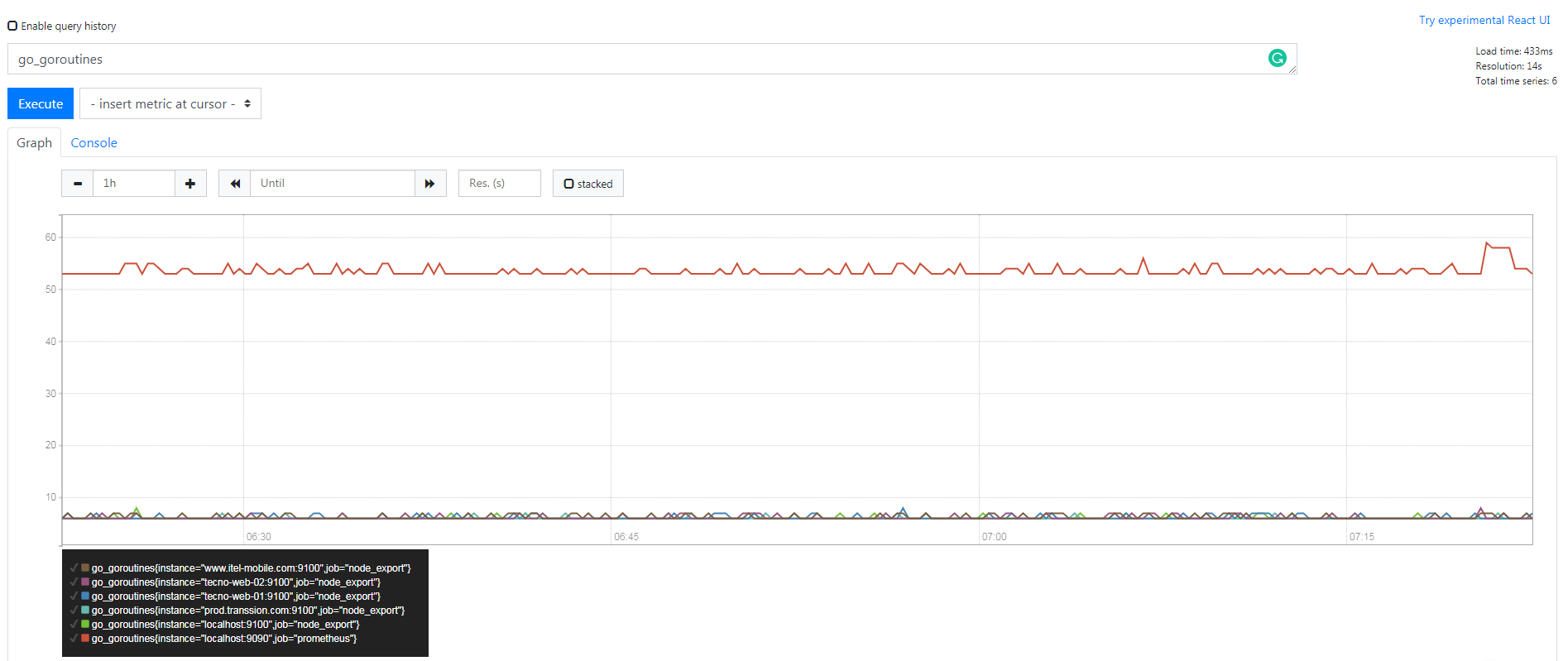
Histogram
- 可以理解为柱状图,典型的应用如:请求持续时间,响应大小。
- 可以对观察结果采样,分组及统计。
例如,查询 prometheus_http_request_duration_seconds_sum{handler=“/api/v1/query”,instance=“localhost:9090”,job=“prometheus”}时,返回结果如下:
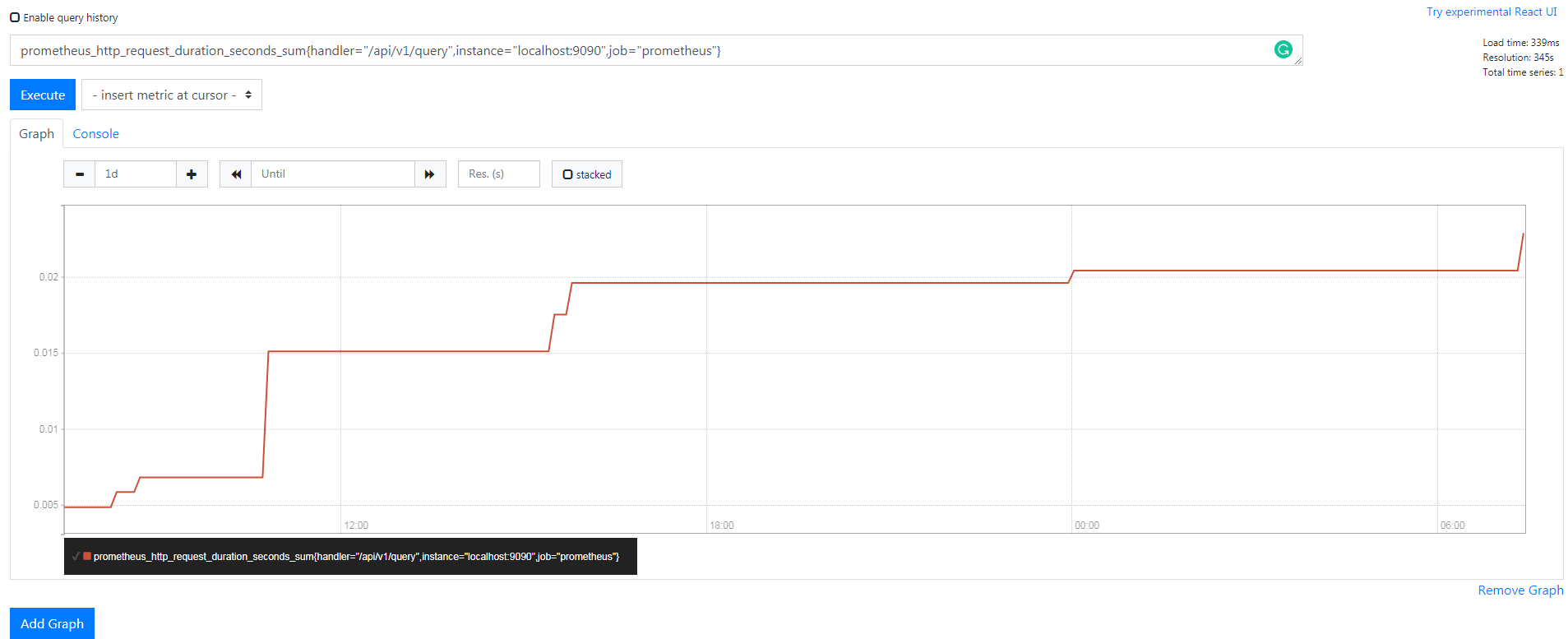
Summary
- 类似于 Histogram, 典型的应用如:请求持续时间,响应大小。
- 提供观测值的 count 和 sum 功能。
- 提供百分位的功能,即可以按百分比划分跟踪结果。
4.3、instance 和 jobs
Prometheus 中,将任意一个独立的数据源(target)称之为实例(instance)。包含相同类型的实例的集合称之为作业(job)。 如下是一个含有四个重复实例的作业:
- job: api-server
- instance 1: 1.2.3.4:5670
- instance 2: 1.2.3.4:5671
- instance 3: 5.6.7.8:5670
- instance 4: 5.6.7.8:5671
自生成标签和时序
Prometheus 在采集数据的同时,会自动在时序的基础上添加标签,作为数据源(target)的标识,以便区分:
- job: The configured job name that the target belongs to.
- instance: The : part of the target’s URL that was scraped.
如果其中任一标签已经在此前采集的数据中存在,那么将会根据 honor_labels 设置选项来决定新标签。详见官网解释: scrape configuration documentation
对每一个实例而言,Prometheus 按照以下时序来存储所采集的数据样本:
-
up{job=“”, instance=“”}: 1 表示该实例正常工作
-
up{job=“”, instance=“”}: 0 表示该实例故障
-
scrape_duration_seconds{job=“”, instance=“”} 表示拉取数据的时间间隔
-
scrape_samples_post_metric_relabeling{job=“”, instance=“”} 表示采用重定义标签(relabeling)操作后仍然剩余的样本数
-
scrape_samples_scraped{job=“”, instance=“”} 表示从该数据源获取的样本数
其中 up 时序可以有效应用于监控该实例是否正常工作。
五、其他监控工具
在前言中,简单介绍了我们选择 Prometheus 的理由,以及使用后给我们带来的好处。
在这里主要和其他监控方案对比,方便大家更好的了解 Prometheus。
Prometheus vs Zabbix
- Zabbix 使用的是 C 和 PHP, Prometheus 使用 Golang, 整体而言 Prometheus 运行速度更快一点。
- Zabbix 属于传统主机监控,主要用于物理主机,交换机,网络等监控,Prometheus 不仅适用主机监控,还适用于 -Cloud, SaaS, Openstack,Container 监控。
- Zabbix 在传统主机监控方面,有更丰富的插件。
- Zabbix 可以在 WebGui 中配置很多事情,但是 Prometheus 需要手动修改文件配置。
Prometheus vs Graphite - Graphite 功能较少,它专注于两件事,存储时序数据, 可视化数据,其他功能需要安装相关插件,而 Prometheus 属于一站式,提供告警和趋势分析的常见功能,它提供更强的数据存储和查询能力。
- 在水平扩展方案以及数据存储周期上,Graphite 做的更好。
Prometheus vs InfluxDB - InfluxDB 是一个开源的时序数据库,主要用于存储数据,如果想搭建监控告警系统, 需要依赖其他系统。
- InfluxDB 在存储水平扩展以及高可用方面做的更好, 毕竟核心是数据库。
Prometheus vs OpenTSDB - OpenTSDB 是一个分布式时序数据库,它依赖 Hadoop 和 HBase,能存储更长久数据, 如果你系统已经运行了 Hadoop 和 HBase, 它是个不错的选择。
- 如果想搭建监控告警系统,OpenTSDB 需要依赖其他系统。
Prometheus vs Nagios - Nagios 数据不支持自定义 Labels, 不支持查询,告警也不支持去噪,分组, 没有数据存储,如果想查询历史状态,需要安装插件。
- Nagios 是上世纪 90 年代的监控系统,比较适合小集群或静态系统的监控,显然 Nagios 太古老了,很多特性都没有,相比之下Prometheus 要优秀很多。
Prometheus vs Sensu - Sensu 广义上讲是 Nagios 的升级版本,它解决了很多 Nagios 的问题,如果你对 Nagios 很熟悉,使用 Sensu 是个不错的选择。
- Sensu 依赖 RabbitMQ 和 Redis,数据存储上扩展性更好。
总结 - Prometheus 属于一站式监控告警平台,依赖少,功能齐全。
- Prometheus 支持对云或容器的监控,其他系统主要对主机监控。
- Prometheus 数据查询语句表现力更强大,内置更强大的统计函数。
- Prometheus 在数据存储扩展性以及持久性上没有 InfluxDB,OpenTSDB,Sensu 好。
六、Export
6.1、文本格式
在讨论 Exporter 之前,有必要先介绍一下 Prometheus 文本数据格式,因为一个 Exporter 本质上就是将收集的数据,转化为对应的文本格式,并提供 http 请求。
Exporter 收集的数据转化的文本内容以行 (\n) 为单位,空行将被忽略, 文本内容最后一行为空行
注释
文本内容,如果以 # 开头通常表示注释。
- 以 # HELP 开头表示 metric 帮助说明。
- 以 # TYPE 开头表示定义 metric 类型,包含 counter, gauge, histogram, summary, 和 untyped 类型。
- 其他表示一般注释,供阅读使用,将被 Prometheus 忽略。
采样数据
内容如果不以 # 开头,表示采样数据。它通常紧挨着类型定义行,满足以下格式:
metric_name [
"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"
] value [ timestamp ]
下面是一个完整的例子:
# HELP http_requests_total The total number of HTTP requests.
# TYPE http_requests_total counter
http_requests_total{method="post",code="200"} 1027 1395066363000
http_requests_total{method="post",code="400"} 3 1395066363000
# Escaping in label values:
msdos_file_access_time_seconds{path="C:\\DIR\\FILE.TXT",error="Cannot find file:\n\"FILE.TXT\""} 1.458255915e9
# Minimalistic line:
metric_without_timestamp_and_labels 12.47
# A weird metric from before the epoch:
something_weird{problem="division by zero"} +Inf -3982045
# A histogram, which has a pretty complex representation in the text format:
# HELP http_request_duration_seconds A histogram of the request duration.
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.05"} 24054
http_request_duration_seconds_bucket{le="0.1"} 33444
http_request_duration_seconds_bucket{le="0.2"} 100392
http_request_duration_seconds_bucket{le="0.5"} 129389
http_request_duration_seconds_bucket{le="1"} 133988
http_request_duration_seconds_bucket{le="+Inf"} 144320
http_request_duration_seconds_sum 53423
http_request_duration_seconds_count 144320
# Finally a summary, which has a complex representation, too:
# HELP rpc_duration_seconds A summary of the RPC duration in seconds.
# TYPE rpc_duration_seconds summary
rpc_duration_seconds{quantile="0.01"} 3102
rpc_duration_seconds{quantile="0.05"} 3272
rpc_duration_seconds{quantile="0.5"} 4773
rpc_duration_seconds{quantile="0.9"} 9001
rpc_duration_seconds{quantile="0.99"} 76656
rpc_duration_seconds_sum 1.7560473e+07
rpc_duration_seconds_count 2693
需要特别注意的是,假设采样数据 metric 叫做 x, 如果 x 是 histogram 或 summary 类型必需满足以下条件:
- 采样数据的总和应表示为 x_sum。
- 采样数据的总量应表示为 x_count。
- summary 类型的采样数据的 quantile 应表示为 x{quantile=“y”}。
- histogram 类型的采样分区统计数据将表示为 x_bucket{le=“y”}。
- histogram 类型的采样必须包含 x_bucket{le=“+Inf”}, 它的值等于 x_count 的值。
- summary 和 historam 中 quantile 和 le 必需按从小到大顺序排列。
6.2、常用查询
收集到 node_exporter 的数据后,我们可以使用 PromQL 进行一些业务查询和监控,下面是一些比较常见的查询。
注意:以下查询均以单个节点作为例子,如果大家想查看所有节点,将 instance=“xxx” 去掉即可。
CPU 使用率
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
CPU 各 mode 占比率
avg by (instance, mode) (irate(node_cpu_seconds_total[5m])) * 100
机器平均负载
node_load1{instance="xxx"} // 1分钟负载
node_load5{instance="xxx"} // 5分钟负载
node_load15{instance="xxx"} // 15分钟负载
内存使用率
100 - ((node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes)/node_memory_MemTotal_bytes) * 100
磁盘使用率
100 - node_filesystem_free{instance="xxx",fstype!~"rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs|udev|none|devpts|sysfs|debugfs|fuse.*"} / node_filesystem_size{instance="xxx",fstype!~"rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs|udev|none|devpts|sysfs|debugfs|fuse.*"} * 100
或者你也可以直接使用 {fstype=“xxx”} 来指定想查看的磁盘信息
网络 IO
// 上行带宽
sum by (instance) (irate(node_network_receive_bytes{instance="xxx",device!~"bond.*?|lo"}[5m])/128)
// 下行带宽
sum by (instance) (irate(node_network_transmit_bytes{instance="xxx",device!~"bond.*?|lo"}[5m])/128)
网卡出/入包
// 入包量
sum by (instance) (rate(node_network_receive_bytes{instance="xxx",device!="lo"}[5m]))
// 出包量
sum by (instance) (rate(node_network_transmit_bytes{instance="xxx",device!="lo"}[5m]))
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/101205.html

