
概述
流让你从外部迭代转向内部迭代。
实际上所有的元素只会迭代一次,只是在迭代每个元素时,元素会执行赋予的所有操作。
这种处理数据的方式很有用,因为你让Stream管理如何处理数据。这样Stream API就可以在背后进行多种优化。此外,使用内部迭代的话,Stream API可以决定并行运行你的代码。这要是用外部迭代的话就办不到了,因为你只能用单一线程挨个迭代。
在本章中,你将会看到Stream API支持的许多操作。这些操作能让你快速完成复杂的数据查询,如筛选、切片、映射、查找、匹配和规约。接下来,我们会看看一下特殊的流:数值流、来自文件和数组等多种来源的流,最后是无限流。
筛选和切片
用谓词筛选
筛选各异的元素
流还支持一个叫做distinct的方法,他会返回一个元素各异(根据流所生成元素的hashCode和equals方法的实现)的流。例如,一下代码会筛选出列表中所有的偶数,并确保没有重复。
List<Integer> numbers = Arrays.asList(1,2,1,3,3,2,4);
numbers.stream()
.filter(i -> i % 2)
.distinct()
.forEach(System.out::println);
截短流
流支持limit(n)方法,该方法会返回一个不超过给定长度的流。所需的长度作为参数传递给limit。如果流是有序的,则最多会返回前n个元素。比如,你可以建立一个List,选出热量超过300卡路里的头三道菜:
List<Dish> dishes = menu.stream()
.filter(d -> d.getCalories() > 300)
.limit(3)
.collect(toList());
请注意limit也可以用在无序流上,比如源是一个Set。这种情况下,limit的结果不会以任何顺序排列。
跳过元素
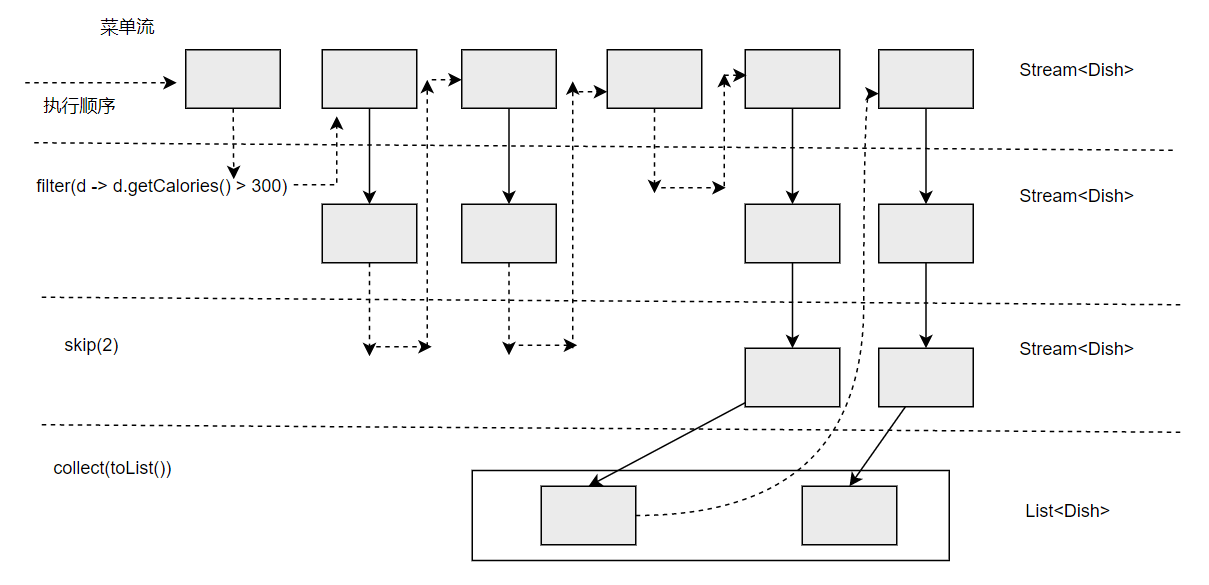
流还支持skip(n)方法,返回一个扔掉了前n个元素的流。如果流中元素不足n个,则返回一个空流。请注意,limit(n)和skip(n)是互补的!例如,下面的代码将跳过300卡路里的头两道菜,并返回剩下的。下图展示查询的迭代过程。
List<Dish> dishes = menu.stream()
.filter(d -> d.getCalories() > 300)
.skip(2)
.collect(toList());
映射
一个非常常见的数据处理套路就是从某些对象中选择信息。比如在SQL里,你可以从表中选择一列。Stream API也通过map和flatMap方法提供类似的工具。
对流中每一个元素应用函数
流的扁平化
对一张单词表,如何返回一张字符列表,列出里面各不相同的字符呢?例如,给定单词列表[“Hello”, “World”],你想要返回列表[“H”, “e”, “l”, “o”, “W”, “r”, “d”]。
你可能会认为这很容易,你可以把每个单词映射成一张字符表,然后调用distinct来过滤重复的字符。第一个版本可能是这样:
List<String> words = Arrays.asList("Hello", "World");
words.stream()
.map(word -> word.split(""))
.distinct()
.collect(Collectors.toList());
这个版本的问题在于,传递给map方法的Lambda为每个单词返回了一个String[]。因此,map返回的流实际上是Stream<String[]>类型的。你真正想要的是用String来表示一个字符流。
尝试使用map和Arrays.stream()
首先,你需要一个字符流,而不是数组流。有一个叫做Arrays.stream()的方法可以接受一个数组并产生一个流,例如:
String[] arrays = {"a", "b", "good"};
Stream<String> stream = Arrays.stream(arrays);
把它用在签名的那个流水线里,看看会发生什么:
List<String> words = Arrays.asList("Hello", "World");
words.stream()
.map(word -> word.split(""))
.map(Arrays::stream)
.distinct()
.collect(Collectors.toList());
当前的解决方案仍然搞不定!这是因为,你现在得到的是一个流的列表Stream<Stream>。实际上,你先是把每个单词转换成一个字母数组,然后把每个数组变成了一个独立的流。
使用flatMap
你可以像下面这样使用flatMap来解决这个问题:
List<String> words = Arrays.asList("Hello", "World");
words.stream()
.map(word -> word.split(""))
.flatMap(Arrays::stream)
.distinct()
.collect(Collectors.toList());
使用flatMap方法的效果是,各个数组并不是分别映射成一个独立的流,而是映射成流的内容。所有使用map(Arrays::stream)时生成的单个流都被合并起来,即扁平化为一个流。
一言以蔽之,flatMap方法让你把一个流中的每一个Stream元素都替换成R元素,最后形成一条Stream。简单的说就是把Stream剥离只保留R,把Stream<Stream>挤压成Stream。
查找和匹配
另一个常见的数据处理套路是看看数据集中的某些元素是否匹配一个给定的属性。Stream API通过allMatch、anyMatch、noneMatch、findFirst和findAny方法提供了这样的工具。
检查谓词是否至少匹配一个元素
anyMatch方法可以回答“流中是否有一个元素能匹配给定的谓词”。比如,你可以用它来看看菜单里面是否有素食可选择:
if(menu.stream().anyMatch(Dish::isVegetarian)) {
System.out.println("The menu is (somewhat) vegetarian frindly!!!");
}
anyMatch方法返回一个boolean,因此是一个终端操作。
检查谓词是否匹配所有元素
- allMatch方法的工作原理和anyMatch类似,但它会看看流中的元素是否都能匹配给定的谓词。
- noneMatch方法与allMatch相对。它可以确保流中没有任何元素与给定的谓词匹配。
短路求值
有些操作不需要处理整个流就能得到结果。例如,假设你需要对一个用and连起来的大布尔表达式求值。不管表达式有多长,你只需要找到一个表达式为false,就可以推断整个表达式将返回false,所以用不着计算整个表达式,这就是短路。
对于流而言,某些操作(例如allMatch、anyMatch、noneMatch、findFirst和findAny)不用处理整个流就能得到结果。只要找到一个元素,就可以有结果了。同样,limit也是一个短路操作:它只需要创建一个给定大小的流,而用不着处理流中所有的元素。在碰到无限大小的流的时候,这种操作就有用了,它们可以把无限流变成有限流。
查找元素
findAny方法将返回当前流中的任意元素。
查找第一个元素
findFirst
有些流有一个出现顺序(encounter order)来指定流中元素出现的逻辑顺序(比如由List或排序好的数据列生成的流)。对于这种流,你可能想要找到第一个元素。为此有一个 findFirst方法,它的工作类似于findAny。例如,给定一个数字列表,下面的代码能照成第一个平方能被3整除的数:
List<Integer> someNumbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> firstSquareDivisibleByThree =
someNumbers.stream()
.map(x -> x*x)
.filter(x -> x % 3 == 0)
.findFirst();
何时使用findFirst和findAny
你可能会想,为什么会有findFirst和findAny两个方法呢?答案是并行。找到第一个元素在并行上限制更多。如果你不关心返回的元素是哪个,请使用findAny,因为它在使用并行流时限制较少,效率较高。
规约
在本节中,你将看到如何把一个流中的元素组合起来,使用reduce操作来表达更复杂的查询,比如“计算菜单中的总卡路里”或“菜单中卡路里最高的菜是哪个”。此类查询需要将流中所有元素反复结合起来,得到一个值。比如一个Integer。这样的查询可以被归类为规约操作(将流规约成一个值)。用函数式编程语言的术语来说,这称为折叠(fold),因为你可以将这个操作看成把一张长长的纸(你的流)反复折叠成一个小方块,而这就是折叠操作的结果。
元素求和
reduce对累加、累乘等这种重复应用的模式做了抽象,你可以像下面这样对流中所有元素求和:
List<Integer> numbers = Arrays.asList(1, 2, 3);
Integer sum = numbers.stream().reduce(0, (a, b) -> a + b);
reduce接受两个参数:
- 一个初始值,这里是0;
- 一个BinaryOperator来将两个元素结合起来产生一个新值,这里我们用的是lambda (a, b) -> a+b。
你也很容易把所有的元素相乘,只需要将另一个Lambda: (a, b) -> a * b 传递给reduce操作就可以了:
int product = numbers.stream().reduce(1, (a,b) -> a * b));
下图展示了reduce操作时如何作用于一个流的:Lambda反复结合每个元素,直到流被规约成一个值。
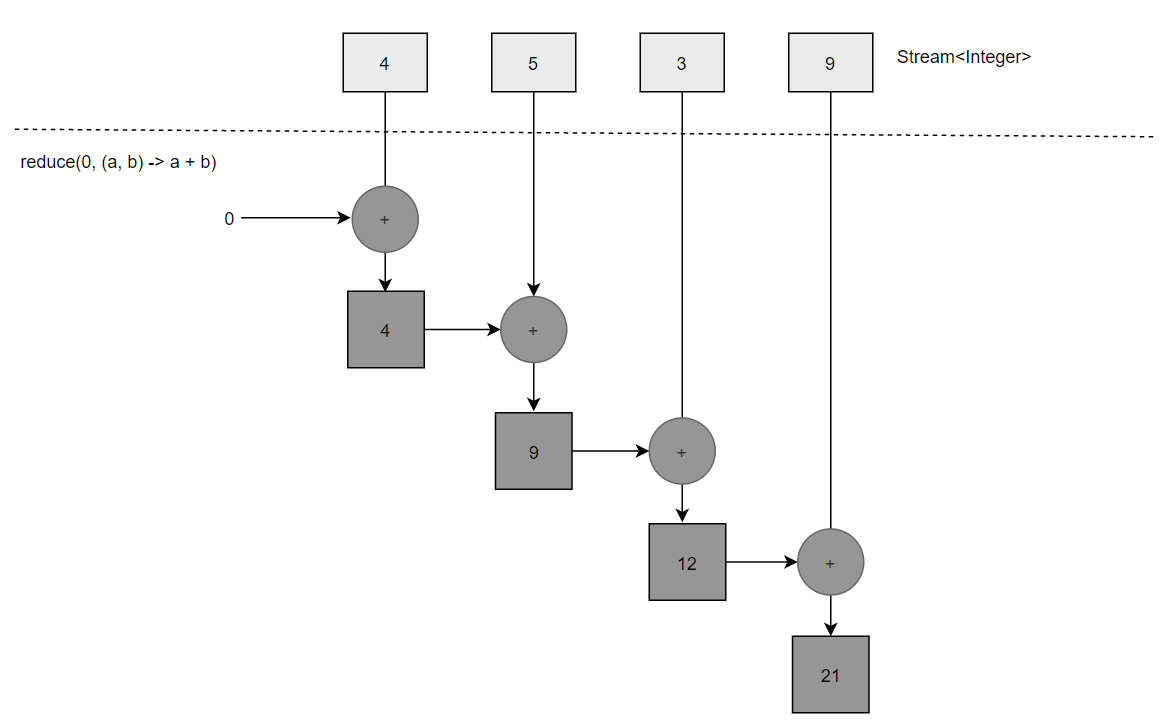

让我们深入研究一下reduce操作是如何对一个数字流求和的。首先,0作为Lambda (a)的第一个参数,从流中获得4作为第二个参数(b)。0 + 4得到4,它成了新的累积值。然后再用累积值和流中下一个元素5调用Lambda,产生新的累积值9。接下来,再用累积值和下一个元素3调用Lambda,得到12。最后,用12和流中最后一个元素9调用Lambda,得到最终结果21。
你可以使用方法引用让这段代码更简洁。在Java 8中,Integer类现在有了一个静态的sum方法来对两个数求和,这恰好是我们想要的,用不着反复用Lambda写同一段代码了:
int sum = numbers.stream().reduce(0, Integer::sum);
无初始值
reduce还有一个重载的变体,它不接受初始值,但是会返回一个Optional对象:
Optional<Integer> sum = numbers.stream().reduce((a, b) -> a + b);
为什么它返回一个Optional呢?考虑流中没有任何元素的情况。reduce操作无法返回其和,因为没有初始值。这就是为什么结果被包裹在一个Optional对象里,以表明和可能不存在。
最大值和最小值
最大值:
Optional<Integer> max = numbers.stream().reduce(Integer::max);
最小值:
Optional<Integer> min = numbers.stream().reduce(Integer::min);
最小值也可以写成Lambda: (x,y) -> x < y ? x : y 而不是Integer::min,不过或者比较易读。
数值流
我们在前面看到了可以使用reduce方法计算流中元素的总和。例如,你可以像下面这样计算菜单的热量:
int calories = menu.stream()
.map(Dish::getCalories)
.reduce(0, Integer::sum);
这段代码的问题是,它有一个暗含的装箱成本。每个Integer都必须拆箱成一个原始类型,再进行求和。要是可以直接向下面这样调用sum方法,岂不是更好?
int calories = menu.stream()
.map(Dish::getCalories)
.sum();
但这是不可能的。问题在于map方法会生成一个Stream。虽然流中的元素是Integer类型,但Stream接口没有定义sum方法。为什么没有呢?比方说,你只有一个像menu那样的Stream,把各种菜加起来是没有任何意义的。但不要担心,Stream API还提供了原始类型流特化,专门支持处理数值流的方法。
原始类型流特化
Java 8引入了三个原始类型特化流接口来解决这个问题:IntStream、DoubleStream和LongStream,分别将流中的元素特化为int、long和double,从而避免了暗含的装箱成本。每个接口都带来了进行常用数值规约的新方法,比如对数值流求和的sum,找到最大元素的max。此外还有在必要时再把它们转换会对象流的方法。要记住的是,这些特化的原因并不在于流的复杂性,而是装箱造成的复杂性一一即类似int和Integer之间的效率差异。
映射到数值流
将流转换为特化版的常用方法是mapToInt、mapToDouble和mapToLong。这些方法和前面说的map方法的工作方式一样,只是它们返回的是一个特化流,而不是Stream。例如,你可以像下面这样用mapToInt对menu中的卡路里求和:
int caloriesd = menu.stream()
.mapToInt(Dish::getCalories)
.sum();
这里,mapToInt会从每道菜中提取热量(用一个Integer表示),并返回一个IntStream(而不是Stream)。然后你就可以调用IntStream接口中定义的sum方法,对卡路里求和了!请注意,如果流是空的,sum默认返回0。IntStream还支持其他的方便方法,如max、min、average等。
转换回对象流
同样,一旦有了数值流,你可能会想把它转换回非特化流。例如,IntStream上的操作只能产生原始整数:IntStream的map操作接受的Lambda必须接受int并返回int(一个IntUnaryOperator)。但是你可能想要生成另一类值,比如Dish。为此,你需要访问Stream接口中定义的那些更广义的操作。要把原始流转换成一般流(每个int都会装箱成一个Integer),可以使用boxed方法,如下所示:
IntStream intStream = menu.stream().mapToInt(Dish::getCalories);
Stream<Integer> stream = intStream.boxed();
默认值OptionalInt
求和的那个例子很容易,因为它有一个默认值:0。但是,如果你要计算IntStream中的最大元素,就得换个法子,因为0是错误的结果。如何区分没有元素的流和最大值真的是0的流呢?Optional可以用Integer、String等参考类型来参数化。对于三种原始流特化,也分别有一个Optional原始类型特化版本:OptionalInt、OptionalDouble和OptionalLong。
例如,要找到IntStream中的最大元素,可以调用max方法,它会返回一个OptionalInt:
OptionalInt maxCalories = menu.stream()
.mapToInt(Dish::getCalories)
.max();
现在,如果没有最大值的话,你就可以显示处理OptionalInt去定义一个默认值了。
int max = maxCalories.orElse(1);
数值范围
和数字打交道时,有一个常用的东西就是数值范围。比如,假设你想要生成1和100之间的所有数字。Java 8引入了两个可以用于IntStream和LongStream的静态方法,帮助生成这种范围:range和rangeClosed。这两个方法都是第一参数接受起始值,第二个参数接受结束值。但range是不包含结束值的,而rangeClosed则包含结束值。让我们来看一个例子:
IntStream evenNumbers = IntStream.rangeClosed(1, 100)
.filter(n -> n % 2 == 0);
System.out.println(evenNumbers.count());
这里我们用了rangeClosed方法来生成1到100之间的所有数字。它会产生一个流,然后你可以链接filter方法,只选出偶数。到目前为止还没有进行任何计算。最后,你对生成的流调用count。因为count是一个终端操作,所以他会处理流,并返回结果50。
构建流
由值创建流
Stream<String> stringStream = Stream.of("java 8", "lambda", "in", "action");
stringStream.map(String::toUpperCase).forEach(System.out::println);
你可以使用静态方法Stream.of,通过显示值创建一个流。它可以接受任意数量的参数。例如,以下代码直接使用Stream.of创建了一个字符串流。然后,你可以将字符串转换为答谢。
你可以使用empty得到一个空流,如下所示
Stream<String> emtpyStream = Stream.empty();
由数组创建流
int[] numbers = {2, 3, 5, 7, 11 ,13};
System.out.println(Arrays.stream(numbers).sum());
你可以使用静态方法Arrays.stream从数组创建一个流。它接受一个数组作为参数。
由文件生成流
Java中用于处理文件等I/O操作的NIO API(非阻塞I/O)已更新,以便利用Stream API。java.nio.file.Files中的很多静态方法都会返回一个流。例如,一个很有用的方法时Files.lines,它会返回一个由指定文件中的各行构成的字符串流。
try(Stream<String> lines = Files.lines(Paths.get("D:\\test.txt"), Charset.defaultCharset())) {
lines.flatMap(line -> Arrays.stream(line.split(" ")))
.distinct()
.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
你可以使用Files.lines得到一流,其中的每个元素都是给定文件中的一行。然后,你可以对line调用split方法将行拆分成单词。应该注意的是,你该如何使用flatMap产生一个扁平的单词流,而不是给没一行生成一个单词流。最后,把distinct方法去重。
由函数生成流:创建无限流
Stream API提供了两个静态方法来从函数生成流:Stream.iterate和Stream.generate。这两个操作可以创建所谓的无限流:不像从固定集合创建的流那样有固定大小的流。由iterate和generate产生的流会用给定的函数按需创建值,因此可以无穷无尽的计算下去!一般来说,应该使用limit(n)来对这种流加以限制,以避免打印无穷多个值。
小结
这一章很长,但是很有收获!现在你可以更高效地处理集合了。事实上,流让你可以简洁地表达复杂的数据处理查询。此外,流可以透明地并行化。以下是你应该从本章学到的关键概念。
- Stream API可以表达复杂的数据处理查询。
- 你可以使用filter、distinct、skip和limit对流做筛选和切片。
- 你可以使用map和flatMap提取或转换流中的元素。
- 你可以使用findFirst和findAny方法查找流中的元素。你可以用allMatch、noneMatch和anyMatch方法让流匹配给定的谓词。
- 这些方法都利用了短路:找到结果就立即停止计算;没有必要处理整个流。
- 你可以利用reduce方法将流中所有的元素迭代合并成一个结果,例如求和或查找最大的元素。
- filter、map等操作是无状态的,它们并不存储任何状态。reduce等操作要存储状态才能计算出一个值。sorted和distinct等操作也要存储状态,因为它们需要把流中的所有元素缓存起来才能返回一个新的流。这种操作称为有状态操作。
- 流有三种基本的原始类型特化:IntStream、DoubleStream和LongStream。它们的操作也有相应的特化。
- 流不仅可以从集合创建,也可以从值、数组、文件以及iterate与generate等特定方法创建。
- 无限流是没有固定大小的流。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/100157.html

