
概述
Elasticsearch索引字段中定义了一些特殊数据类型,用于反映某些特殊的数据关系或数据表示方法。由于这些数据类型都与一组DSL查询和聚集查询相关联,所以本书在第2章2.3节中并没有介绍它们,而是集中在本章统一介绍。这些特殊数据类型主要包括join类型、nested类型和地理坐标,本章将在8.1~8.3节中分别介绍它们。
除了DSL和聚集查询以外,Elasticsearch在Basic授权中还提供了一种基于SQL语法的查询语言,这种查询语言可以以类似SQL语言的形式执行文档检索。由于这种SQL语言在Kibana画布功能中需要使用,所以本章在最后一小节会对它做简要介绍。
8.1 父子关系
Elasticsearch中的父子关系是单个索引内部文档与文档之间的一种关系,父文档与子文档同属一个索引并通过父文档_id建立联系,类似于关系型数据库中单表内部行与行之间的自关联。
8.1.1 join类型
在Elasticsearch中并没有外键的概念,文档之间的父子关系通过给索引定义join类型字段实现。例如创建一个员工索引employees,定义一个join类型的management字段用于确定员工之间的管理与被管理关系:示例8-1 创建join 类型字段
PUT employees
{
"mappings":{
"properties":{
"management":{
"type":"join",
"relations":{
"manager":"member"
}
}
}
}
}
在示例8-1中,management字段的数据类型被定义为join,同时在该字段的relations参数中定义父子关系为manager与member,其中manager为父而member为子,它们的名称可由用户自定义。文档在父子关系中的地位,是在添加文档时通过join类型字段指定的。还是以employees索引为例,在向employees索引中添加父文档时,应该将management字段设置为manager;而添加子文档时则应该设置为member。具体如下:8-2 父子关系添加文档
PUT /employees/_doc/1
{
"name":"tom",
"management":{
"name":"manager"
}
}
PUT /employees/_doc/2?routing=1
{
"name":"smith",
"management":{
"name":"member",
"parent":1
}
}
PUT /employees/_doc/3?routing=1
{
"name":"john",
"management":{
"name":"member",
"parent":1
}
}
在示例8-2中,编号为1的文档其management字段通过name参数设置为manager,即在索引定义父子关系中处于父文档的地位;而编号为2和3的文档其management字段则通过name参数设置为member,并通过parent参数指定了它的父文档为编号1的文档。在使用父子关系时,要求父子文档必须要映射到同一分片中,所以在添加子文档时routing参数是必须要设置的。显然父子文档在同一分片可以提升在检索时的性能,可在父子关系中使用的查询方法有has_child、has_parent和parent_id查询,还有parent和children两种聚集。
8.1.2 has_child查询
has_child查询是根据子文档检索父文档的一种方法,它先根据查询条件将满足条件的子文档检索出来,在最终的结果中会返回具有这些子文档的父文档。例如,如果想检索smith的经理是谁,可以按示例8-3请求:

在示例8-3中,has_child查询的type参数需要设置为父子关系中子文档的名称member,这样has_child查询父子关系时就限定在这种类型中检索;query参数则设置了查询子文档的条件,即名称为smith。最终结果会根据smith所在文档,通过member对应的父子关系检索它的父文档。
8.1.3 has_parent查询
has_parent查询与has_child查询正好相反,是通过父文档检索子文档的一种方法。在执行流程上,has_parent查询先将满足查询条件的父文档检索出来,但在最终返回的结果中展示的是具有这些父文档的子文档。例如,如果想查看tom的所有下属,可以按示例8-4请求:

has_parent查询在结构上与has_child查询基本相同,只是在指定父子关系时使用的参数是parent_type而不是type。
8.1.4 parent_id查询
parent_id查询与has_parent查询的作用相似,都是根据父文档检索子文档。不同的是,has_parent可以通过query参数设置不同的查询条件;而parent_id查询则只能通过父文档_id做检索。例如,查询_id为1的子文档:

以上三种查询都属于DSL,基本逻辑都是通过子文档检索父文档,或是通过父文档检索子文档。接下来再来看看针对父子关系的聚集查询。
8.1.5 children聚集
如果想通过父文档检索与其关联的所有子文档就可以使用children聚集。同样以employess索引为例,如果想要查看tom的所有下属就可以按示例8-6的方式检索:
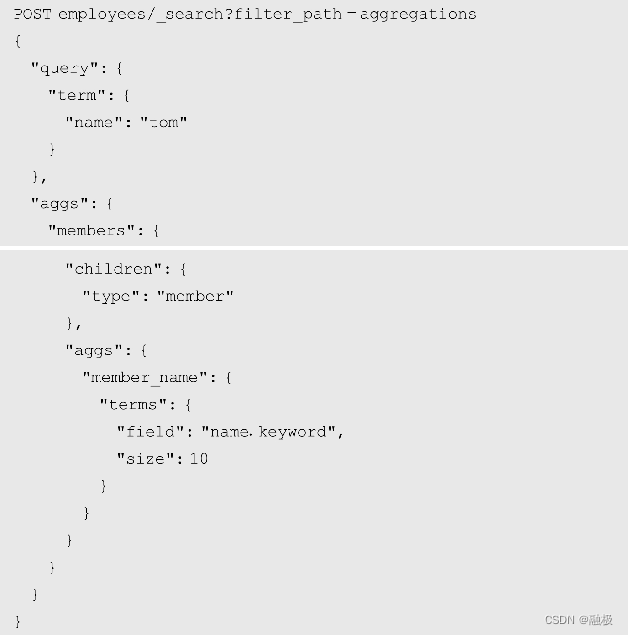
在示例8-6中,query参数设置了父文档的查询条件,即名称字段name为tom的文档;而聚集查询members中则使用了children聚集将它的子文档检索出来,同时还使用了一个嵌套聚集member_name将子文档name字段的词项全部展示出来了。
8.1.6 parent聚集
parent聚集与children聚集正好相反,它是根据子文档查找父文档,parent聚集在Elasticsearch版本6.6以后才支持。例如通过name字段为smith的文档,查找该文档的父文档:

8.2 嵌套类型
本书第2.3节介绍的对象类型虽然可按JSON对象格式保存结构化的对象数据,但由于Lucene并不支持对象类型,所以Elasticsearch在存储这种类型的字段时会将它们平铺为单个属性。例如:

在示例8-8中的colleges文档,address字段会被平铺为address.country和address.city两个字段存储。这种平铺存储的方案在存储单个对象时没有什么问题,但如果在存储数组时会丢失单个对象内部字段的匹配关系。例如:

示例8-9中的colleges文档在实际存储时,会被拆解为“"address.country":["CN","US"]”和“"address.city":["BJ","NY"]”两个数组字段。这样一来,单个对象内部country字段和city字段之间的匹配关系就丢失了。换句话说,使用CN与NY作为共同条件检索文档时,上述文档也会被检索出来,这在逻辑上就出现了错误:

在示例8-10中使用了bool组合查询,要求country字段为CN而city字段为NY。这样的文档显然并不存在,但由于数组中的对象被平铺为两个独立的数组字段,文档1仍然会被检索出来。
8.2.1 nested类型
为了解决对象类型在数组中丢失内部字段之间匹配关系的问题,Elasticsearch提供了一种特殊的对象类型nested。这种类型会为数组中的每一个对象创建一个单独的文档,以保存对象的字段信息并使它们可检索。由于这类文档并不直接可见,而是藏匿在父文档之中,所以本书后续章节将称这类文档为隐式文档或嵌入文档。还是以colleges索引为例,将它的address字段设置为nested类型:

当字段被设置为nested类型后,再使用示例8-10中的bool组合查询就不能检索出来了。这是因为对nested类型字段的检索实际上是对隐式文档的检索,在检索时必须要将检索路由到隐式文档上,所以必须使用专门的检索方法。也就是说,现在即使将示例8-10中的查询条件设置为CN和BJ也不会检索出结果。nested类型字段可使用的检索方法包括DSL的nested查询,还有聚集查询中的nested和reverse_nested两种聚集。
8.2.2 nested查询
nested查询只能针对nested类型字段,需要通过path参数指定nested类型字段的路径,而在query参数中则包含了针对隐式文档的具体查询条件。例如:

在示例8-12中再次使用CN与NY共同作为查询条件,但由于使用nested类型后会将数组中的对象转换成隐式文档,所以在nested查询中将不会有文档返回了。读者可以自行将上面条件更换为CN和BJ,看是否有文档返回。
除了path和query两个参数以外,nested查询还包括score_mode和ignore_unmapped两个参数。前者用于指定嵌入对象如何影响相关度,可选值包括avg、max、min、sum和none,其中avg为默认值。ignore_unmapped用于控制在path参数指向出错时的行为,默认情况下为false,即在出错时会抛出异常。
8.2.3 nested聚集
nested聚集是一个单桶聚集,也是通过path参数指定nested字段的路径,包含在path指定路径中的隐式文档都将落入桶中。所以nested字段保存数组的长度就是单个文档落入桶中的文档数量,而整个文档落入桶中的数量就是所有文档nested字段数组长度的总和。有了nested聚集,就可以针对nested数组中的对象做各种聚集运算,例如:

在示例8-13中,nested_address是一个nested聚集的名称,它会将address字段的隐式文档归入一个桶中。而嵌套在nested_address聚集中的city_names聚集则会在这个桶中再做terms聚集运算,这样就将对象中city字段所有的词项枚举出来了。
8.2.4 reverse_nested聚集
reverse_nested聚集用于在隐式文档中对父文档做聚集,所以这种聚集必须作为nested聚集的嵌套聚集使用。例如:

在示例8-14中,city_names聚集也是将隐式文档中city字段的词项全部聚集出来。不同的是在这个聚集中还嵌套了一个名为avg_age_in_city的聚集,这个聚集就是一个reverse_nested聚集。它会在隐式文档中将city字段具有相同词项的文档归入一个桶中,而avg_age_in_city聚集嵌套的另外一个名为avg_age的聚集,它会把落入这个桶中文档的age字段的平均值计算出来。所以从总体上来看,这个聚集的作用就是将在同一城市中大学的平均校龄计算出来。
8.3 地理信息
8.4 使用SQL语言
Elasticsearch在Basic授权中支持以SQL语句的形式检索文档,SQL语句在执行时会被翻译为DSL执行。从语法的角度来看,Elasticsearch中的SQL语句与RDBMS中的SQL语句基本一致,所以对于有数据库编程基础的人来说大大降低了使用Elasticsearch的学习成本。除此之外,由于在Kibana新提供的画布功能中不支持使用Elasticsearch聚集查询功能,所以如果需要使用聚集查询时就必须要使用Elasticsearch SQL定义。
Elasticsearch提供了多种执行SQL语句的方法,可使用类似_search一样的REST接口执行也可以通过命令行执行。它甚至还提供了JDBC和ODBC驱动来执行SQL语句,但JDBC和ODBC属于Platinum(白金版)授权需要付费,所以本小节将只介绍_sql接口。
8.4.1 _sql接口
在早期版本中,Elasticsearch执行SQL的REST接口为_xpack/sql,但在版本7以后这个接口已经被废止而推荐使用_sql接口。例如:

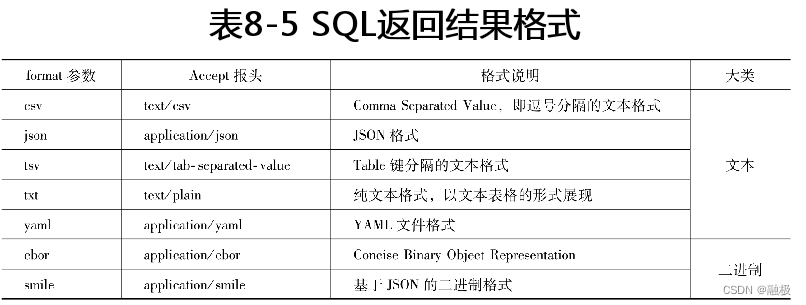
在示例8-27中,_sql接口通过query参数接收SQL语句,而SQL语句也包含有select、from、where、order by等子句。_sql接口的URL请求参数format定义了返回结果格式,也可以通过在调用_sql接口时设置Accept请求报头设置返回结果格式。比如在示例8-27中定义了返回结果格式为txt,而将该请求报头Accept设置为text/plain也可以实现相似的效果。除了txt以外,_sql接口还支持csv、json、tsv、txt、yaml、cbor、smile格式。其中,cbor和smile是两种二进制格式,适用于通过程序解析的应用场景。有关这些格式的说明,请参考表8-5。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/100102.html

